Visual Analytics zur Technologiefrüherkennung
Die Forschungsgruppe „Human-Computer Interaction und Visual Analytics“ erforscht und entwickelt Visual Analytics Lösungen zur frühen Erkennung von Trends.
Ein Beitrag von Prof. Dr. Kawa Nazemi
Donnerstag, 14. Februar 2019
ikum
Die Analyse von Daten in unterschiedlichen Bereichen zur Markt- und Strategieentwicklung spielt bereits heute für viele Unternehmen eine essentielle Rolle. Insbesondere dann, wenn diese Unter-nehmen auf technologische Innovationen angewiesen sind und neue Produkte und Prozesse zum Erfolg führen wollen, um so die Wirtschaftlichkeit des Unternehmens zu stärken. Obgleich Unter-nehmen in den letzten Jahren immer mehr verstanden haben, wie wichtig die Analyse großer und unstrukturierter Daten ist, um die Entwicklungen des Marktes früh zu erkennen und schnell auf Ver-änderungen zu reagieren, wissen vor allem viele kleine und mittelständische Unternehmen nicht, wie solche komplexen Datenanalysen mit den verfügbaren Mitteln und Werkzeuge umzusetzen sind. Bisher existiert im Bereich der Datenanalyse zur Marktentwicklung eine große Lücke, die bislang vornehmlich von Beratungsunternehmen mit großem Aufwand geschlossen wird, speziell wenn es sich dabei um frühe Trends handelt und nicht um bereits etablierte Technologien und Trends in sozialen Netzwerken, News und Geschäftsberichten. Diese sogenannten frühen Signale erfordern nämlich nicht nur eine Analyse durch maschinelle Lernverfahren, um aufkommende Trends aufzuzeigen, sondern auch die menschliche Interaktion und Intervention, um die genutzten Parameter auf eigene Bedürfnisse anzupassen [1]. Es sind demnach zwei wesentliche Aspekte im Analyseprozess zu berücksichtigen: 1) welche Daten lassen sehr frühe Trends erkennen und 2) wie kann der Mensch im Analyse Prozess involviert werden [2].
Sehr frühe Indikatoren für die Erkennung neuer und vor allem für die Gesellschaft und Wirtschaft wichtige Technologien können wissenschaftliche Publikationen liefern. Diese stellen meist Technologien, Ansätze oder Methoden bereits Jahre vor einer Markteinführung vor. Ein erwähnenswertes Beispiel hierzu ist die Arbeit von Blei und Kollegen [3], die bereits 2003 einen Ansatz entwickelten, die mit statistischen Methoden Themen (sogenannte Topics) aus Texten extrahiert. Viele Jahre wurde der Ansatz nicht wirklich beachtet und fand seinen Weg nicht in die reale Anwendung. Heute nutzen alle Anbieter von Business Intelligence (BI) und Datenanalyse Lösungen diesen Ansatz. Es ist zu einem defacto Standard in der Textanalyse geworden. Unternehmen hätten demnach durch eine adäquate Analyse das Potential des Ansatzes erkennen und diese frühzeitig in ihrem Portfolio aufnehmen können. Doch bei so vielen neuen Technologien und Methoden ist eine rein maschinelle Analyse nicht immer vorteilhaft. Methoden der künstlichen Intelligenz (KI) lernen meist durch sogenannte Trainingsdaten, die nicht jeden Aspekt der technologischen Früherkennung aufdecken können. Auch wenn Methoden angewendet werden, die reale Daten als Grundlage des Trainings nehmen und mit der Zeit weiterlernen, fehlt es dennoch nicht nur an realer Intelligenz, sondern auch an Transparenz. Der Mensch wird in diesem Prozess gar nicht oder nur rudimentär einbezogen, obgleich er bei Weitem eine höhere und vor Allem breitere Intelligenz besitzt als aktuelle Ansätze der KI. Hier bringen Methoden der visuellen Analyse oder besser bekannt als Visual Analytics (VA) die Modelle der KI und die menschliche Intelligenz zusammen. Visual Analytics kombiniert demnach automatische Analysetechniken mit interaktiven Visualisierungen, um ein effektives Verstehen (Transparenz), Schlussfolgern und Entscheidungsfindung zu ermöglichen [4]. Erweiterte Ansätze ermöglichen gerade durch die visuelle Repräsentation auch diagnostische (weshalb ist etwas passiert), prädiktive (was wird in Zukunft wahrscheinlich passieren) und „prescriptive“ Ansätze, die mögliche Handlungsempfehlungen visualisieren.
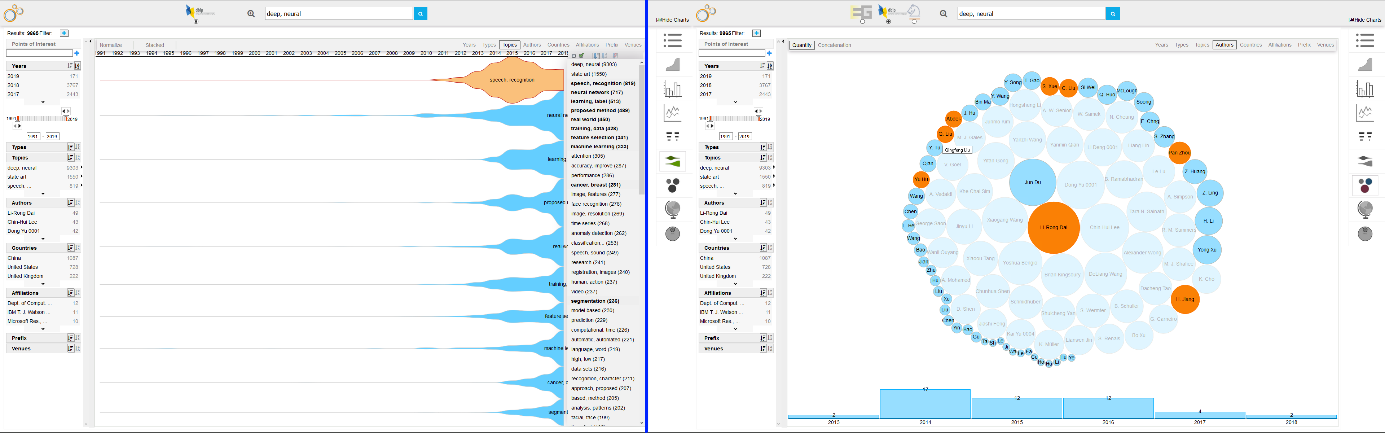
Die Forschungsgruppe „Human-Computer Interaction und Visual Analytics“ der Hochschule Darmstadt erforscht und entwickelt seit mehreren Jahren Visual Analytics Lösungen zur Marktanalyse, Technologie- und Innovationsmanagement und insbesondere zur frühen Erkennung von Trends. Dabei wird die gesamte Datentransformation von unstrukturierten Daten bis hin zu interaktiven visuellen Lösungen unter Nutzung maschineller Lernverfahren und Methoden der KI erforscht [5]. Dabei geht die Forschungsgruppe immer von den individuellen Faktoren der Anwendungsfälle aus. Abbildung 1 zeigt eine Übersicht aktueller Trends in der Informatikforschung basierend auf automatisch angereicherten und extrahierten Informationen.

In der folgenden Abbildung 2 hat der Benutzer bereits interagiert und sieht zum einen Themen, die stark mit „deep neural“ in Verbindung stehen und zum anderen jene Autoren und deren Koautoren, die am Meisten zu diesem Thema weltweit publiziert haben.
Ein entsprechendes Video, das einen Eindruck einer der Lösungen vermitteln soll, findet sich unter dem folgenden Link: https://www.youtube.com/watch?v=Ku-ggbV4moY .
Quellen:
[1] Obermaier, H.; Bensema, K. & Joy, K. I. Visual Trends Analysis in Time-Varying Ensembles. IEEE Transactions on Visualization and Computer Graphics, 2016.
[2] Nazemi, K., Retz, R., Burkhardt, D., Kuijper, A., Kohlhammer, J. and Fellner, D. W: Visual trend analysis with digital libraries. In Proceedings of i-KNOW ’15. ACM, New York, NY, USA, Article 14 DOI=http://dx.doi.org/10.1145/2809563.2809569, 2015.
[3] Blei, D. M, Ng, A. Y and Jordan, M. I.: Latent Dirichlet Allocation. Journal of Machine Learning Research 3 (2003) 993-1022. 2003.
[4] Keim D., Kohlhammer J., Ellis G., Mansmann F.: Matering the Information Age Solving Problems with Visual Analytics. Eurographics Association, 2010.
[5] Nazemi, K.: Adaptive Semantics Visualization. Studies in Computational Intelligence. Springer International Publishing, 2016.

Kawa Nazemi ist Professor für Human-Computer Interaction und Visual Analytics an der Hochschule Darmstadt. Dort lehrt und forscht er in den Bereichen Mensch-Computer-Interaktion, Informationsvisualisierung, maschinelles Lernen, Data Analytics und Visual Analytics. Er ist „Mitglied des hessischen Promotionszentrum Angewandte Informatik und leitet die Forschungsgruppe „Human-Computer Interaction & Visual Analytics“ an der Hochschule Darmstadt. Nazemi forschte zwischen 2007 und 2016 am Fraunhofer IGD, leitete dort ab 2011 die Gruppe Semantik Visualisierung, die benutzerzentrierte Visualisierungslösungen entwickelte und war stellv. Abteilungsleiter. Kawa Nazemi promovierte am Fachbereich Informatik der TU Darmstadt zu adaptiven und intelligenten Visualisierungen. Er war verantwortlich für eine Vielzahl nationaler und europäischer Projekte und diverser Forschungsaufträge der Industrie. Er ist Autor von über 70 peer-reviewed Publikationen und Mitglied diverser Programmkomitees. Seine Forschungsarbeiten wurden u. a. von der Academia Europaea mit dem Burgen Scholarship Award und der European Association for Artificial Intelligence gewürdigt.
Webseiten:
https://kawa.nazemi.net
https://vis.h-da.de



